source("codigos/SIGEH_isochrone.R")Cálculos de accesibilidad
Modelo de accesibilidad
Se utilizará un modelo de accesibilidad carretera que se construye a partir de rasters de
Modelo digital de elevación (pendiente en grados)
Tipo de uso de suelo (clasificado por coeficiente de fricción)
Red vial de INEGI (versión Diciembre 2025)
El modelo se construye en “codigos/SIGEH_isochrone.R” y se almacena como archivo .rds
Se carga el modelo de accesibilidad
Lo anterior define una matriz de transición entre píxeles de resolución 200 m, por lo que nos permite calcular rutas óptimas entre pares de puntos (píxeles) y obtener el costo (en minutos) de recorrer estas rutas.
Dado que el modelo de accesibilidad es la base de este proyecto, se describe su uso para la generación de archivos estáticos.
Cálculo de accesibilidad para CLUES y AGEBs
Demográficos
Los requerimientos mínimos que debe contener el archivo es del catálogo de variables de INEGI, en este caso, con desagregación de AGEB o localidad rural con las siguientes variables
CVEGEO, Municipio, Localidad
POB1, POB42, POB84, POB17:POB25
SALUD1:SALUD10
En este proyecto se calcularán las siguientes variables para cada AGEB/ Localidad rural
Tiempo promedio a CLUES nivel \(k\) más cercano, para \(k=1,2,3\)
Nombre y tiempo promedio al CLUES nivel 2 más cercano
Número de CLUES nivel \(k\) a menos de \(T\) minutos, con \(k=1,2,3\) y \(T=10,20,40,60.\)
Se describirá el proceso generalizado y se concluye con la referencia al código para su implementación.
Sea \(A\) un polígono, que representa un AGEB o una localidad rural. Sea \(k\) el nivel de atención seleccionado y consideramos \(C_k\) el conjunto de CLUES en operación de nivel \(k\) con el mismo sistema de georeferencia que A.
Se calcula utilizando el modelo de accesibilidad el costo de traslado en minutos de cada pixel del estado de Hidalgo con resolución de 200m. Para este AGEB \(A\), se filtran los centroides de los píxeles del raster de costo de traslado que tienen intersección no vacía con el polígono. Si la intersección fuera vacía, significa que el polígono seleccionado se encuentra por encima del límite de tiempo definido por el modelo (300 m ), que se traduce en que el AGEB seleccionado está fuera del área de cobertura.
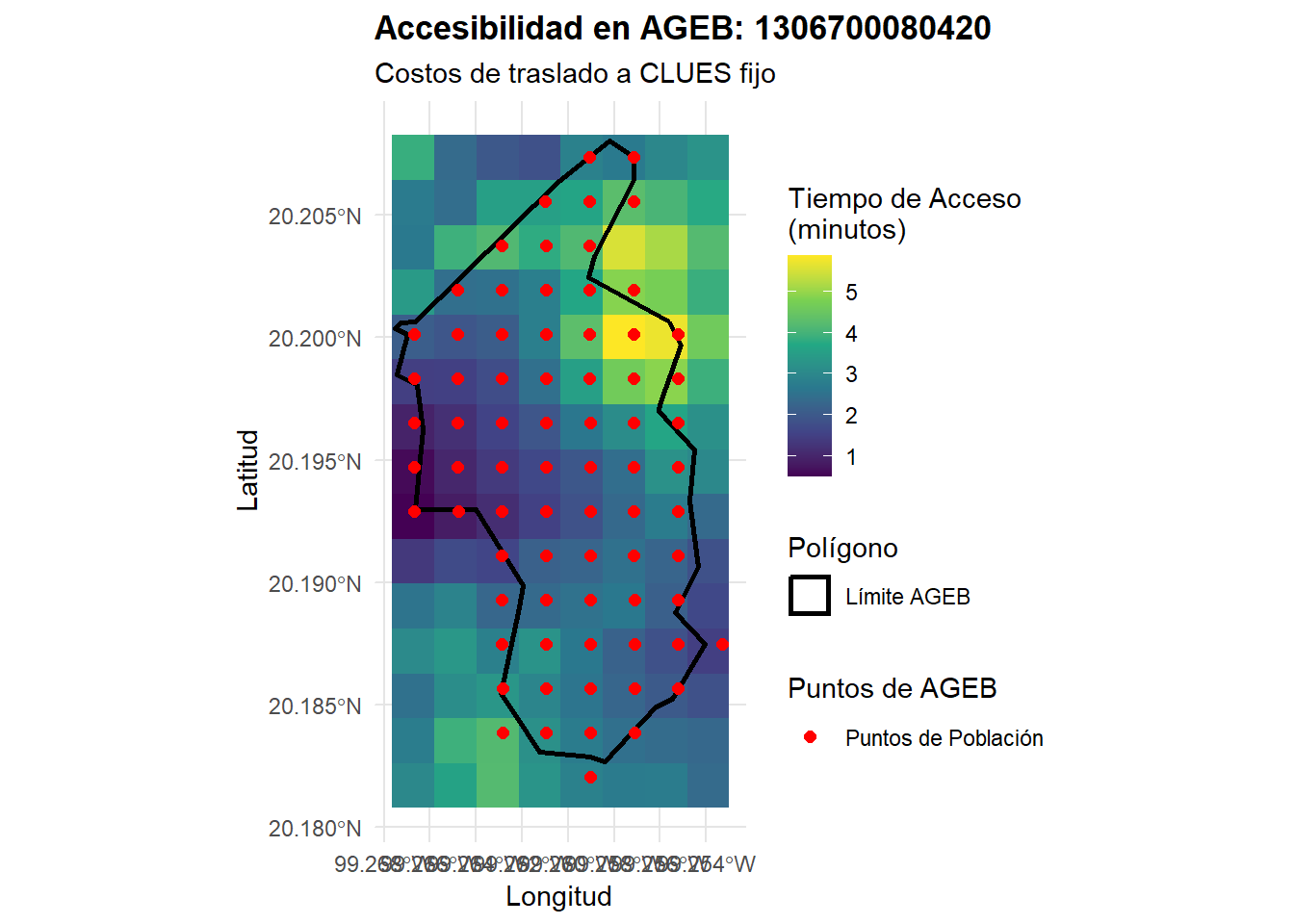
El enfoque alternativo para calcular los costos de traslado entre polígonos (AGEB) y puntos (CLUES) sería considerar el centroide del polígono, sin embargo este enfoque contaminaría los datos para los casos de AGEBs grandes en extensión territorial. Por otro lado, en el enfoque de extracción de puntos, se considera el promedio de costos de traslados entre los puntos origen (AGEB) y destino (CLUES), que se puede interpretar como un promedio de costo de traslado entre varias zonas del mismo AGEB.
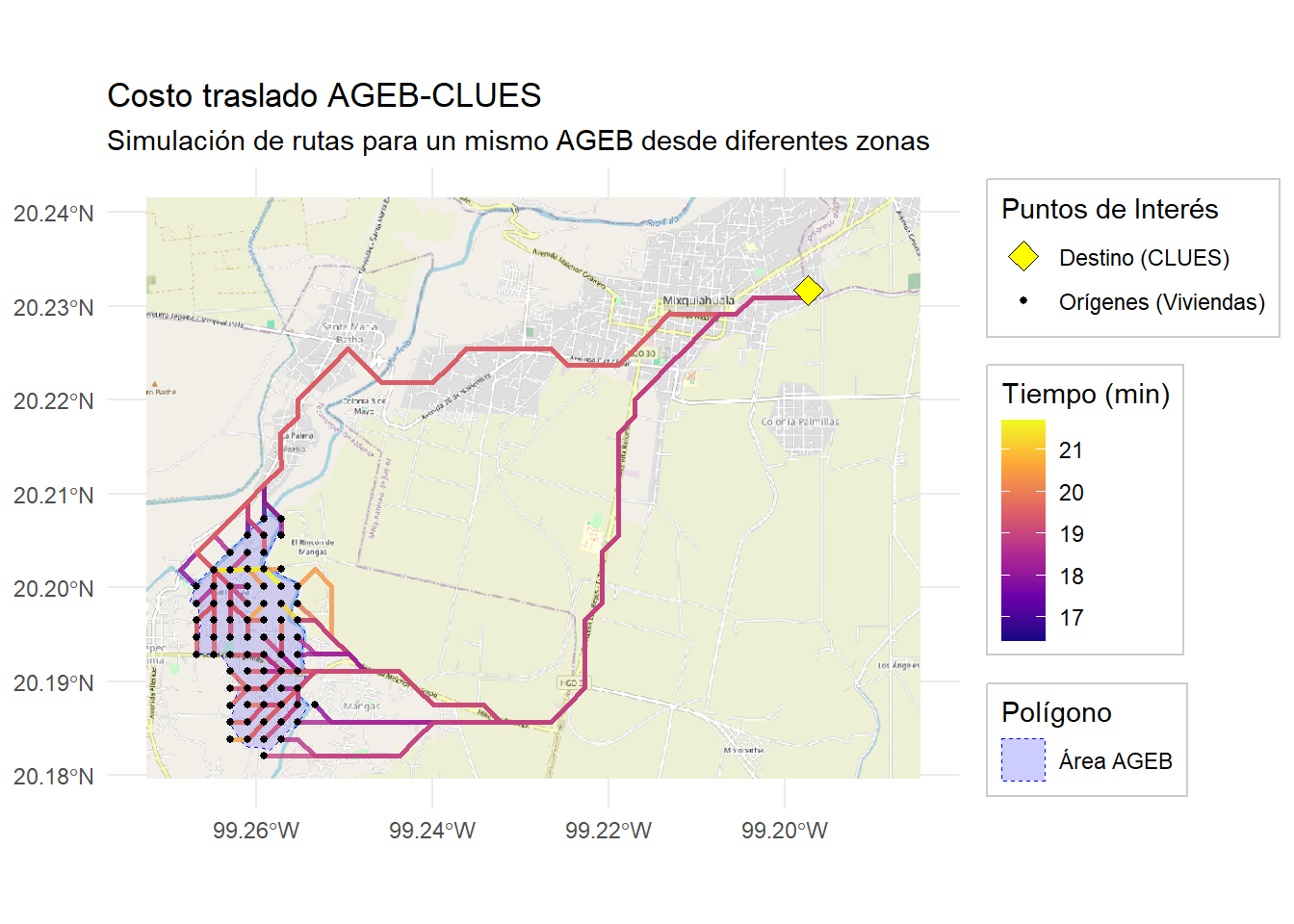
Lo anterior se repite para cada CLUES lo cual define una matriz de costos de dimensión \(|C_k|\times {|\text{puntos de AGEB}|}\) . De esta matriz podemos extraer información valiosa que corresponde a:
Tiempo a CLUES nivel \(k\) más cercano, que corresponde al mínimo de los promedios de los renglones.
Número de CLUES nivel \(k\) a menos de \(T\) minutos, que corresponde al número de elementos del vector definido por el promedio de renglones que satisface ser menor a \(T\).
Cuando \(k=2\), se conserva el índice del elemento mínimo de la suma por renglones, pues corresponde al hospital más cercano.
CLUES
Los requerimientos mínimos que debe contener el archivo provisto por Salud son
CLUES (código único)
Nivel de atención (1er nivel, 2do nivel o 3er nivel)
Georeferenciación (lat+lon / geometry) y una referencia al sistema utilizado (E.g. EPSG:4326)
En este proyecto se calcularán las siguientes variables para cada CLUES
Número de CLUES de tipo \(k\) a menos de \(T\) minutos, con \(k=1,2,3\) y \(T=10,20,40,60.\)
Tiempo promedio al CLUES de nivel \(k\) más cercano, con \(k=1,2,3\).
Nombre y CLUES nivel \(k\) más cercano, con \(k=1,2,3.\)
Estimaciones de población en rangos de tiempo \(T\), con \(T=10,20,40,60.\)
Sea \(C\) el conjunto de CLUES en operación de cualquier nivel de atención.
A través del modelo de accesibilidad se construye una matriz de costos de traslado de CLUES a CLUES.
Notemos que si \(n\) es el número de renglones de esta matriz de costos, entonces \(n=|C_1|+|C_2|+|C_3|\) y la matriz de costos \(M\) contiene 3 bloques en la diagonal correspondiente a los costos de accesibilidad entre CLUES de nivel \(k\), con \(k=1,2,3\), mientras que fuera de la diagonal se encuentran los costos entre CLUES de niveles \(i\), \(j\) con \(i\neq j\).
Con esto en mente, podemos dividir cada renglón en 3 sub-renglónes de longitudes correspondientes al número de CLUES de cada nivel de atención \(k\)
\[ \text{Renglón i-ésimo} =(\underbrace{M_{i,1},M_{i,2},\ldots,M_{i,|C_{1}|}}_{\text{Costos de traslado desde i a CLUES de nivel 1}},\overbrace{M_{i,1+|C_{1}|},\ldots,M_{i,|C_2|+|C_{1}|}}^{\text{Costos de traslado desde i a CLUES de nivel 2}},\underbrace{\ldots,M_{i,|C_3|+|C_2|+|C_{1}|}}_{\text{Costos de traslado desde i a CLUES de nivel 3}}) \]
Cada sub-renglón corresponde a los costos de traslado del CLUES seleccionado hacia los diferentes CLUES separados por nivel de atención, de manera que de estos sub-renglones es suficiente para calcular:
El número de CLUES de nivel \(k\) a menos de \(T\) minutos, que corresponde a calcular el número de elementos de cada sub-renglón que es menor a \(T\).
Tiempo promedio al CLUES de nivel \(k\) más cercano, que corresponde al mínimo de cada sub-renglón. Naturalmente, cuando el CLUES seleccionado y el sub-renglón corresponden al mismo nivel de atención, tomamos el segundo mínimo.
De conservar el índice del mínimo de cada sub-renglón o del segundo mínimo según sea el caso, éste corresponde al CLUES más cercano.
Para la estimaciones de población en un rango de tiempo \(T\), se consideran los polígonos de AGEBs y localidades rurales, y con el método para raster “extract”, se extrae el conjunto de píxeles que lo cubren y se guarda la proporción de cobertura de los píxeles respecto a la totalidad del AGEB. Por ejemplo, un AGEB podría tener una cobertura de 25% con un valor de 5 minutos, además de un 75% de cobertura con un valor de 5.5 minutos, con lo que se construirá una estimación que involucra al 100% de la población del AGEB si consideramos un tiempo menor o igual a 5.5 minutos.
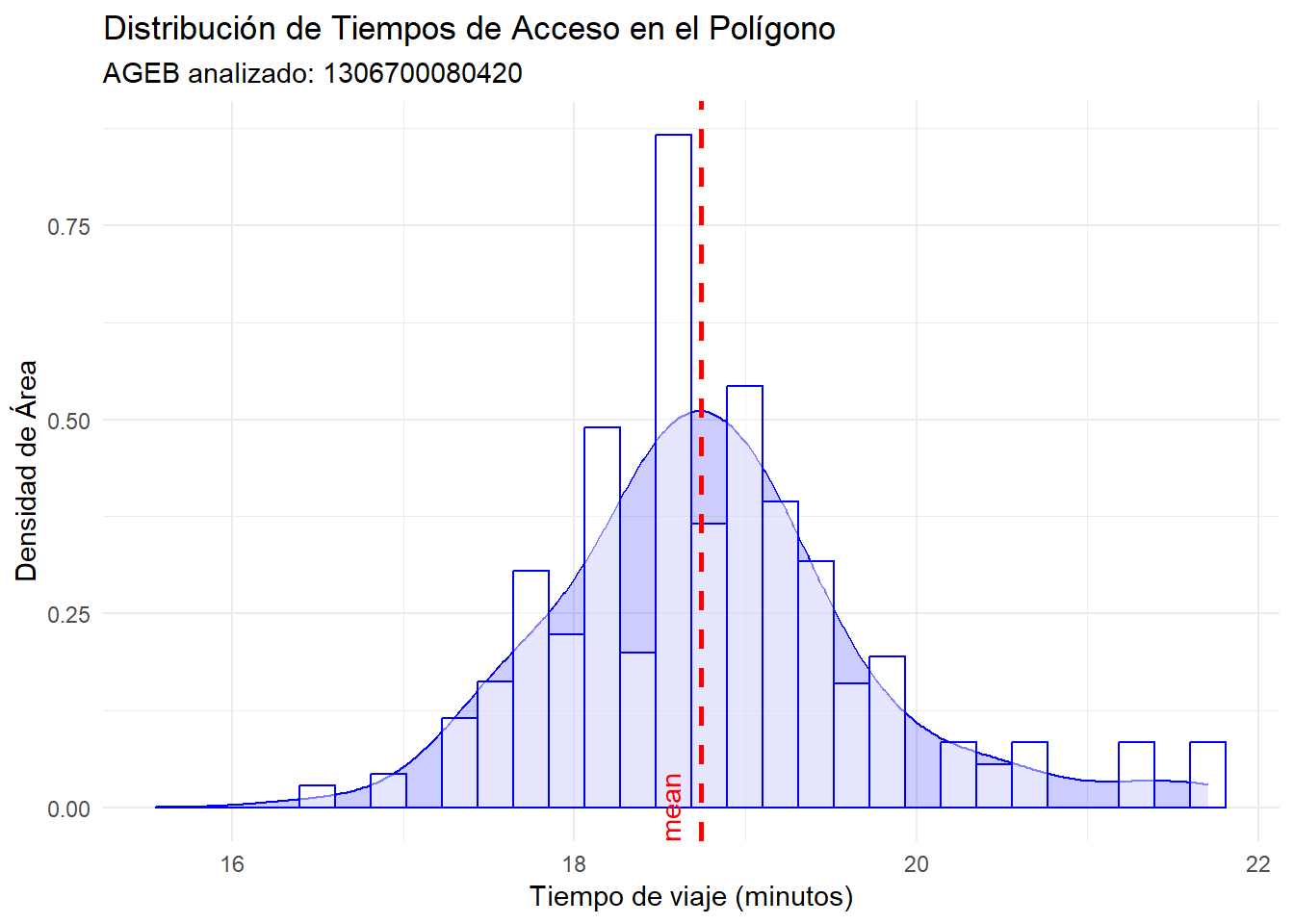
De lo anterior se define una densidad de cobertura con peso igual al costo de traslado. La suma por rangos de tiempo de los AGEBs involucrados definiría las estimaciones de población por rangos de tiempo.
Anexo
Código para generar los archivos .geojson que alimentan la app.R
## Se leen las geometrías de los AGEBS:
demograficos_scince=st_read("outputs/demograficos_cartograficos_scince_20.geojson")
##Este se construye con el marco Geoestadístico de INEGI, se le aplica un buffer a las localidades rurales de tipo punto y se hace una simplificación de geometrías para reducir el tamaño (MB) del .geojson
##Se leen los CLUES
source("codigos/csv_to_geojson.R")
#
local <- DBI::dbConnect(RSQLite::SQLite(), tempfile("clues_en_operacion.sqlite"))
st_write(clues_en_operacion_s, local, "clues_en_operacion", delete_layer = FALSE)
clues_en_operacion=dplyr::tbl(local,"clues_en_operacion")
##Definimos los rasters de accesibilidad
#Solo necesitamos las ubicaciones de los CLUES clasificados por nivel y me genera los rasters a cada tipo de atención (1,2,3, _)
source("codigos/no_usar_calculos_rasters_accesibilidad.R")
source("codigos/no_usar_conteo_cluesN1_por_rangos_tiempo.R")
'source("codigos/no_usar_conteo_cluesN1_por_rangos_tiempo.R")
median uq max neval
23842.38 23842.38 23842.38 1'
source("codigos/no_usar_calculos_accesibilidad_clues.R")Se incorporan los cálculos generados en archivos .geojson
#inputs
demograficos_scince=sf::st_read("outputs/demograficos_cartograficos_scince_20.geojson")
clues_en_operacion_s=sf::st_read("outputs/clues_en_operacion.geojson") |> dplyr::arrange(NIVEL.ATENCION)
#outputs
demograficos_info_accesibilidad_clues=sf::st_read("outputs/demograficos_info_accesibilidad_clues.geojson")
aportaciones_de_ageb_por_clues=read.csv("outputs/aportaciones_de_ageb_por_clues.csv")
metricas_clues=read.csv("outputs/metricas_clues.csv")
conteo_por_nivel_de_atencion=clues_en_operacion_s |> sf::st_drop_geometry()|> dplyr::group_by(NIVEL.ATENCION) |> dplyr::summarise(conteo=dplyr::n())
#union
n1=conteo_por_nivel_de_atencion$conteo[1]
n2=conteo_por_nivel_de_atencion$conteo[2]
n3=conteo_por_nivel_de_atencion$conteo[3]
demograficos_info_accesibilidad_clues=demograficos_info_accesibilidad_clues |>
dplyr::mutate(
id_clues_N1_mas_cercano=metricas_clues$CLUES[as.numeric(id_clues_N1_mas_cercano)]
) |>
dplyr::mutate(
id_clues_N2_mas_cercano=metricas_clues$CLUES[(as.numeric(id_clues_N2_mas_cercano)+n1)]) |>
dplyr::mutate(
id_clues_N3_mas_cercano=metricas_clues$CLUES[(as.numeric(id_clues_N3_mas_cercano)+n1+n2)]
)
nombres_clues=clues_en_operacion_s |>
sf::st_drop_geometry() |>
dplyr::select(CLUES, NOMBRE.DE.LA.UNIDAD)
demograficos_info_accesibilidad_clues = demograficos_info_accesibilidad_clues |>
dplyr::left_join(nombres_clues, by = c("id_clues_N1_mas_cercano" = "CLUES")) |>
dplyr::rename(nombre_clues_N1_mas_cercano = NOMBRE.DE.LA.UNIDAD) |>
dplyr::relocate(nombre_clues_N1_mas_cercano, .after = id_clues_N1_mas_cercano) |>
# --- Nivel 2 ---
dplyr::left_join(nombres_clues, by = c("id_clues_N2_mas_cercano" = "CLUES")) |>
dplyr::rename(nombre_clues_N2_mas_cercano = NOMBRE.DE.LA.UNIDAD) |>
dplyr::relocate(nombre_clues_N2_mas_cercano, .after = id_clues_N2_mas_cercano) |>
# --- Nivel 3 ---
dplyr::left_join(nombres_clues, by = c("id_clues_N3_mas_cercano" = "CLUES")) |>
dplyr::rename(nombre_clues_N3_mas_cercano = NOMBRE.DE.LA.UNIDAD) |>
dplyr::relocate(nombre_clues_N3_mas_cercano, .after = id_clues_N3_mas_cercano)
demograficos_info_accesibilidad_clues=demograficos_info_accesibilidad_clues |> dplyr::mutate(
dplyr::across(c(CLUES_N1_10:CLUES_N1_60,
CLUES_N2_10:CLUES_N2_60,
CLUES_N3_10:CLUES_N3_60), as.numeric),
dplyr::across(c(tiempo_promedio_clues_N1_mas_cercano,
tiempo_promedio_clues_N2_mas_cercano,
tiempo_promedio_clues_N3_mas_cercano), \(x) round(as.numeric(x), 2))
)
clues_en_operacion_s=clues_en_operacion_s |>
merge(y=metricas_clues,by='CLUES')
clues_en_operacion_s=clues_en_operacion_s |>
merge(y=aportaciones_de_ageb_por_clues,by='CLUES')
#guardar
sf::st_write(clues_en_operacion_s,"outputs/clues_en_operacion_con_info_accesibilidad.geojson",driver='GeoJSON',append=F,delete_dsn = T)
sf::st_write(demograficos_info_accesibilidad_clues,"outputs/demograficos_con_info_accesibilidad.geojson",driver='GeoJSON',append=F,delete_dsn = T)
#guardar en un solo archivo
limites_municipales=sf::st_read("inputs/accesibilidad_SIGEH/hidalgo/LIM_MUNICIPALES.shp") |> sf::st_transform(4326)
con <- DBI::dbConnect(RSQLite::SQLite(), "clues_demograficos_municipios.sqlite")
sf::st_write(clues_en_operacion_s, con, "clues_en_operacion", delete_layer = T)
sf::st_write(limites_municipales, con, "limite_municipal", delete_layer = T)
sf::st_write(demograficos_info_accesibilidad_clues , con, "demograficos_scince", delete_layer = T)
DBI::dbDisconnect(con)